如今各类AI模型层出不穷,百花齐放,大佬们开发的速度永远遥遥领先于学习者的学习速度。。为了解放生产力,不让应用层开发人员受限于各语言模型的生产部署中..LangChain横空出世界。
Langchain可以说是现阶段十分值得学习的一个AI架构,那么究竟它有什么魔法才会配享如此高的地位呢?会不会学习成本很高?不要担心!Langchain虽然功能强大,但其实它就是一个为了提升构建LLM相关应用效率的一个工具,我们也可以将它理解成一个“说明书",是的,只是一个“说明书”!它标准的定义了我们在构建一个LLM应用开发时可能会用到的东西。比如说在之前写过的AI文章中介绍的prompt,就可以通过Langchain中的PromptTemplate进行格式化:
prompt="""Translatethetext\thatisdelimitedbytriplebackticks\intoastylethatis{style}.\text:```{text}```"""当我们调用ChatPromptTemplate进行标准化时
_template=_template(prompt)print(prompt_template,'ChatPromptTemplate')
该prompt就会被格式化成:
从上述例子,可以直观的看到ChatPromptTemplate可以将prompt中声明的输入变量style和text准确提取出来,使prompt更清晰。当然,Langchain对于prompt的优化不止这一种方式,它还提供了各类其他接口将prompt进一步优化,这里只是举例一个较为基础且直观的方法,让大家感受一下。
Langchain其实就是在定义多个通用类的规范,去优化开发AI应用过程中可能用到的各类技术,将它们抽象成多个小元素,当我们构建应用时,直接将这些元素堆积起来,而无需在重复的去研究各"元素"实现的细枝末节。
二、官方文档Langchain这么长,我怎么看?毋庸置疑,想要学习Langchain最简单直接的方法就是阅读官方文档,先贴一个链接Langchain官方文档
通过文档目录我们可以看到,Langchain由6个module组成,分别是ModelIO、Retrieval、Chains、Memory、Agents和Callbacks。
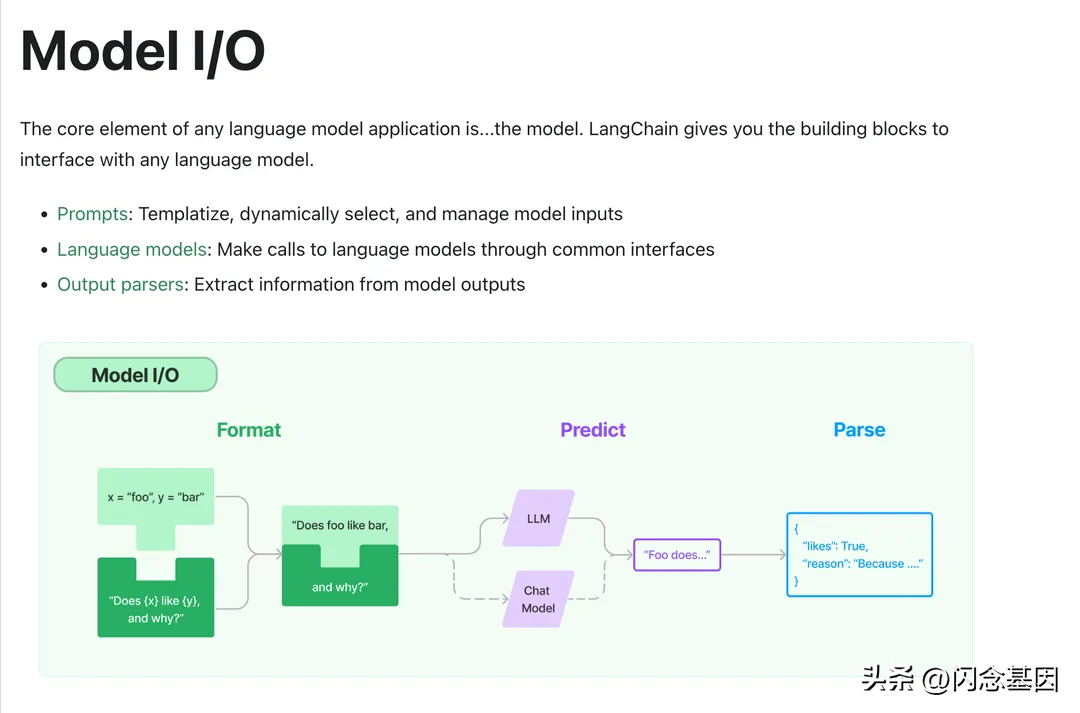
ModelIO:AI应用的核心部分,其中包括输入、Model和输出。
Retrieval:“检索“——该功能与向量数据密切库相关,是在向量数据库中搜索与问题相关的文档内容。
Memory:为对话形式的模型存储历史对话记录,在长对话过程中随时将这些历史对话记录重新加载,以保证对话的准确度。
Chains:虽然通过ModelIO、Retrieval和Memory这三大模块可以初步完成应用搭建,但是若想实现一个强大且复杂的应用,还是需要将各模块组合起来,这时就可以利用Chains将其连接起来,从而丰富功能。
Agents:它可以通过用户的输入,理解用户的意图,返回一个特定的动作类型和参数,从而自主调用相关的工具来满足用户的需求,将应用更加智能化。
Callbacks:回调机制可以调用链路追踪,记录日志,帮助开发者更好的调试LLM模型。

好了,说到这我们只要一个一个module去攻破,最后将他们融会贯通,也就成为一名及格的Langchain学习者了。
三、ModelIO这一部分可以说是Langchain的核心部分,引用一下之前介绍AI时用过的图,介绍了ModelIO内部的一些具体实现原理)


Langchain对于prompt的优化:主要是致力于将其优化成为可移植性高的Prompt,以便更好的支持各类LLM,无需在切换Model时修改Prompt。通过官方文档可以看到,Prompt在Langchain被分成了两大类,一类是Prompttemplate,另一类则是Selectors。
Propmpttemplate:这个其实很好理解就是利用Langchain接口将prompt按照template进行一定格式化,针对Prompt进行变量处理以及提示词的组合。
Selectors:则是指可以根据不同的条件去选择不同的提示词,或者在不同的情况下通过Selector,选择不同的example去进一步提高Prompt支持能力。
3.1.1模版格式:在prompt中有两种类型的模版格式,一是f-string,这是十分常见的一类prompt,二是jinja2。
f-string是以后版本中引入的一种特性,用于在字符串中插入表达式的值。语法简洁,直接利用{}花括号包裹变量或者表达式,即可执行简单的运算,性能较好,但是只限用在py中。
Output:Tellmeafunnyjokeaboutchickens.
jinja2常被应用于网页开发,与Flask和Django等框架结合使用。它不仅支持变量替换,还支持其他的控制结构(例如循环和条件语句)以及自定义过滤器和宏等高级功能。此外,它的可用性范围更广,可在多种语境下使用。但与f-string不同,使用jinja2需要安装相应的库。
Output:Tellmeafunnyjokeaboutchickens.
总结一下:如果只需要基本的字符串插值和格式化,首选f-string,因为它的语法简洁且无需额外依赖。但如果需要更复杂的模板功能(例如循环、条件、自定义过滤器等),jinja2更合适。
3.1.1.2PropmptTemplate:
在prompttemplate这一部分中需要掌握的几个概念:
1️⃣基本提示模版:
大多是字符串或者是由对话组成的数组对象。对于创建字符串类型的prompt要了解两个概念,一是input_variables属性,它表示的是prompt所需要输入的变量。二是format,即通过input_variables将prompt格式化。比如利用PromptTemplate进行格式化。
默认情况下,PromptTemplate使用Python的语法进行模板化;但是可以使用其他模板语法(例如,jinja2)prompt_template=_template("Tellmea{adjective}jokeabout{content}.")print(prompt_(adjective="funny",content="chickens"))Output如下(该例子就是将两个input_variables分别设置为funny和chickens,然后利用format分别进行赋值。若在template中声明了input_variables,利用format进行格式化时就一定要赋值,否则会报错,当在template中未设置input_variables,则会自动忽略。)
Tellmeafunnyjokeaboutchickens.
当对对话类型的prompt进行格式化的时候,可以利用ChatPromptTemplate进行:
可以使用()方法创建部分提示模板。partial_prompt=(foo="foo")print(partial_(bar="baz"))除上述方法,部分函数声明和普通的prompt一样,也可以直接用partial_variables去声明prompt=PromptTemplate(template="Tellmea{adjective}jokeabouttheday{date}",input_variables=["adjective"],partial_variables={"date":_get_datetime})Output如下:
Tellmeafunnyjokeabouttheday12/08/2022,16:25:30
3️⃣组成提示词模版:
可以通过()方法将多个提示词组合到一起。如下示例,生成了full_prompt和introduction_prompt进行近一步组合。
_template="""{introduction}{example}"""full_prompt=_template(full_template)introduction_template="""YouareimpersonatingElonMusk."""introduction_prompt=_template(introduction_template)example_template="""Here'sanexampleofaninteraction"""example_prompt=_template(example_template)input_prompts=[("introduction",introduction_prompt),("example",example_prompt),]pipeline_prompt=PipelinePromptTemplate(final_prompt=full_prompt,pipeline_prompts=input_prompts)4️⃣自定义提示模版:
在创建prompt时,我们也可以按照自己的需求去创建自定义的提示模版。官方文档举了一个生成给定名称的函数的英语解释例子,在这个例子中函数名称作为输入,并设置提示格式以提供函数的源代码:
(function_name)初始化字符串promptPROMPT="""\提供一个函数名和源代码并给出函数的相应解释函数名:{function_name}源代码:{source_code}解释:"""classFunctionExplainerPromptTemplate(StringPromptTemplate,BaseModel):"""一个自定义提示模板,以函数名作为输入,并格式化提示模板以提供函数的源代码。"""@validator("input_variables")defvalidate_input_variables(cls,v):"""验证输入变量是否正确。"""iflen(v)!=1or"function_name"notinv:raiseValueError("函数名必须是唯一的输入变量。")returnvdefformat(self,**kwargs)-str:源代码+名字提供给promptprompt=(function_name=kwargs["function_name"].__name__,source_code=source_code)returnpromptdef_prompt_type(self):return"function-explainer"FunctionExplainerPromptTemplate接收两个变量一个是prompt,另一个则是传入需要用到的model,该class下面的validate_input_variables用来验证输入量,format函数用来输出格式化后的prompt.
定义函数test_adddeftest_add():return1+1配置一个格式化程序,该格式化程序将prompt格式化为字符串。此格式化程序应该是一个PromptTemplate对象。example_prompt=PromptTemplate(input_variables=["question","answer"],template="Question:{question}\n{answer}")print(example_(**examples[0]))最后用FewShotPromptTemplate来创建一个提示词模板,该模板将输入变量作为输入,并将其格式化为包含示例的提示词。prompt=FewShotPromptTemplate(example_selector=example_selector,example_prompt=example_prompt,suffix="Question:{input}",input_variables=["input"])print(prompt)除了上述普通的字符串模版,聊天模版中也可以采用此类方式构建一个带例子的聊天提示词模版:
,FewShotChatMessagePromptTemplate提示词模板,用于格式化每个单独的示例。example_prompt=_messages([("human","{input}"),("ai","{output}"),])few_shot_prompt=FewShotChatMessagePromptTemplate(example_prompt=example_prompt,examples=examples)print(few_shot_())
6️⃣独立化prompt:
为了便于共享、存储和加强对prompt的版本控制,可以将想要设定prompt所支持的格式保存为JSON或者YAML格式文件。也可以直接将待格式化的prompt单独存储于一个文件中,通过格式化文件指定相应路径,以更方便用户加载任何类型的提示信息。
创建json文件:
{"_type":"prompt","input_variables":["adjective","content"],"template":"Tellmea{adjective}jokeabout{content}."}主文件代码:
_promptprompt=load_prompt("./simple_")print((adjective="funny",content="chickens"))Output如下:
Tellmeafunnyjokeaboutchickens.
这里是直接在json文件中指定template语句,除此之外也可以将template单独抽离出来,然后在json文件中指定template语句所在的文件路径,以实现更好的区域化,方便管理prompt。
创建json文件:
{"_type":"prompt","input_variables":["adjective","content"],"template_path":"./simple_"}simple_:
Tellmea{adjective}jokeabout{content}.其余部分代码同第一部分介绍,最后的输出结果也是一致的。
3.1.1.3Selector:
在fewshot模块,当我们列举一系列示例值,但不进一步指定返回值,就会返回所有的prompt示例,在实际开发中我们可以使用自定义选择器来选择例子。例如,想要返回一个和新输入的内容最为近似的prompt,这时候就可以去选择与输入最为相似的例子。这里的底层逻辑是利用了SemanticSimilarityExampleSelector这个例子选择器和向量相似度的计算(openAIEmbeddings)以及利用chroma进行数据存储,代码如下:
__selector=_examples(用于生成嵌入的嵌入类,这些嵌入用于测量语义相似性。OpenAIEmbeddings(),要生成的示例数。k=1)
然后我们去输入一条想要构建的prompt,遍历整个示例列表,找到最为合适的example。
由于我们使用向量存储来根据语义相似性选择示例,因此我们需要首先填充存储。to_vectorize=["".join(())forexampleinexamples]创建向量库后,可以创建example_selector以表示返回的相似向量的个数提示词模板将通过将输入传递给`select_examples`方法来加载示例example__examples({"input":"horse"})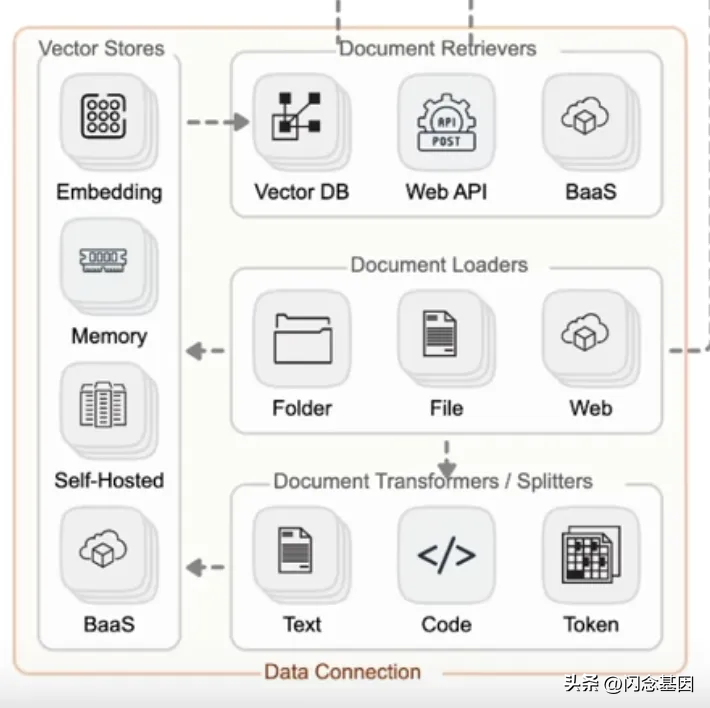
此时就可以返回两个个最相似的例子。接下来我们可以重复fewshot的步骤利用FewShotChatPromptTemplate去创建一个提示词模版。
上文中介绍了在利用Langchain进行应用开发时所常用的构建prompt方式,无论哪种方式其最终目的都是为了更方便的去构建prompt,并尽可能的增加其复用性。Langchain提供的prompt相关工具远不止上文这些,在了解了基础能力后可以进一步查阅官方文档找到最适合项目特点的工具,进行prompt格式化。
3.1.2LLM1.单个调用:直接调用Model对象,传入一串字符串然后直接返回输出值,以openAI为例:
=OpenAI()print(llm('你是谁'))2.批量调用:通过generate可以对字符串列表,进行批量应用Model,使输出更加丰富且完整。
llm_result=(["给我背诵一首古诗","给我讲个100字小故事"]*10)
这时的llm_result会生成一个键为generations的数组,这个数组长度为20项,第一项为古诗、第二项为故事、第三项又为古诗,以此规则排列..
3.异步接口:asyncio库为LLM提供异步支持,目前支持的LLM为OpenAI、PromptLayerOpenAI、ChatOpenAI、Anthropic和Cohere受支持。可以使用agenerate异步调用OpenAILLM。在代码编写中,如果用了科学上网/魔法,以openAI为例,在异步调用之前,则需要预先将openai的proxy设置成为本地代理(这步很重要,若不设置后续会有报错)
定义一个同步方式生成文本的函数defgenerate_serially():llm=OpenAI(temperature=0.9)循环10次resp=(["Hello,howareyou?"])打印生成的文本异步调用agenerate方法生成文本print([0][0].text)定义一个并发(异步)方式生成文本的函数asyncdefgenerate_concurrently():llm=OpenAI(temperature=0.9)创建10个异步任务(*tasks)这个类CustomLLM继承了LLM类,并增加了一个新的类变量n。n:int输入的提示字符串stop:Optional[List[str]]=None,可选的回调管理器,默认为None**kwargs:Any,)-str:返回prompt字符串的前n个字符@property这个方法的文档字符串,说明这个方法的功能是获取标识参数return{"n":}从模块导入FakeListLLM类,此类可能用于模拟或伪造某种行为__定义一个响应列表,这些响应可能是模拟LLM的预期响应responses=["Action:PythonREPL\nActionInput:print(2+2)","FinalAnswer:4"]调用initialize_agent函数,使用上面的tools和llm,以及指定的代理类型和verbose参数来初始化一个代理agent=initialize_agent(tools,llm,agent=_SHOT_REACT_DESCRIPTION,verbose=True)从模块导入HumanInputLLM类,此类可能允许人类输入或交互来模拟LLM的行为__初始化一个HumanInputLLM对象,其中prompt_func是一个函数,用于打印提示信息llm=HumanInputLLM(prompt_func=lambdaprompt:print(f"\n===PROMPT====\n{prompt}\n=====ENDOFPROMPT======"))调用代理的run方法,传递字符串"Whatis'BocchitheRock!'?"作为输入,询问代理关于'BocchitheRock!'的信息("Whatis'BocchitheRock!'?")6.缓存大语言模型:和测试大语言模型具有一样效果的是缓存大语言模型,通过缓存层可以尽可能的减少API的调用次数,从而节省费用。在Langchain中设置缓存分为两种情况:一是在内存中设置缓存,二是在数据中设置缓存。存储在内存中加载速度较快,但是占用资源并且在关机之后将不再被缓存,在内存中设置缓存示例如下:
_cache=SQLiteCache(database_path=".")llm=OpenAI(model_name="text-davinci-002",n=2,best_of=2)start_time=()记录结束时间elapsed_time=_time-start_time记录开始时间print(("用中文讲个笑话"))_time=()计算总时间print(f"Predictmethodtook{elapsed_time:.4f}secondstoexecute.")7.跟踪token使用情况(仅限model为openAI):
_openai_callbackllm=OpenAI(model_name="text-davinci-002",n=2,best_of=2,cache=None)withget_openai_callback()ascb:result=llm("讲个笑话")print(cb)上述代码直接利用get_openai_callback即可完成对于单条的提问时token的记录,此外对于有多个步骤的链或者agent,langchain也可以追踪到各步骤所耗费的token。
___openai_callbackllm=OpenAI(temperature=0)tools=load_tools(["llm-math"],llm=llm)agent=initialize_agent(tools,llm,agent=_SHOT_REACT_DESCRIPTION,verbose=True)withget_openai_callback()ascb:response=("王菲现在的年龄是多少?")print(f"TotalTokens:{_tokens}")print(f"PromptTokens:{_tokens}")print(f"CompletionTokens:{_tokens}")print(f"TotalCost(USD):${_cost}")8.序列化配置大语言模型:Langchain也提供一种能力用来保存LLM在训练时使用的各类系数,比如template、model_name等。这类系数通常会被保存在json或者yaml文件中,以json文件为例,配置如下系数,然后利用load_llm方法即可导入:
_llmllm=load_llm(""){"model_name":"text-davinci-003","temperature":0.7,"max_tokens":256,"top_p":1.0,"frequency_penalty":0.0,"presence_penalty":0.0,"n":1,"best_of":1,"request_timeout":None,"_type":"openai"}亦或者在配置好大模型参数之后,直接利用save方法即可直接保存配置到指定文件中。
("")
9.流式处理大语言模型的响应:流式处理意味着,在接收到第一个数据块后就立即开始处理,而不需要等待整个数据包传输完毕。这种概念应用在LLM中则可达到生成响应时就立刻向用户展示此下的响应,或者在生成响应时处理响应,也就是我们现在看到的和ai对话时逐字输出的效果:可以看到实现还是较为方便的只需要直接调用StreamingStdOutCallbackHandler作为callback即可。
_stdoutimportStreamingStdOutCallbackHandlerllm=OpenAI(streaming=True,callbacks=[StreamingStdOutCallbackHandler()],temperature=0)resp=llm("Writemeasongaboutsparklingwater.")可以看到实现还是较为方便的只需要直接调用StreamingStdOutCallbackHandler作为callback即可。
3.1.3OutputParsersModel返回的内容通常都是字符串的模式,但在实际开发过程中,往往希望model可以返回更直观的内容,Langchain提供的输出解析器则将派上用场。在实现一个输出解析器的过程中,需要实现两种方法:1️⃣获取格式指令:返回一个字符串的方法,其中包含有关如何格式化语言模型输出的说明。2️⃣Parse:一种接收字符串(假设是来自语言模型的响应)并将其解析为某种结构的方法。
1.列表解析器:利用此解析器可以输出一个用逗号分割的列表。
_,ChatPromptTemplate,_modelsimportChatOpenAIoutput_parser=CommaSeparatedListOutputParser()format_instructions=output__format_instructions()prompt=PromptTemplate(template="Listfive{subject}.\n{format_instructions}",input_variables=["subject"],partial_variables={"format_instructions":format_instructions})model=OpenAI(temperature=0)_input=(subject="冰淇淋口味")output=model(_input)output_(output)2.日期解析器:利用此解析器可以直接将LLM输出解析为日期时间格式。
__parser=DatetimeOutputParser()template="""回答用户的问题:{question}{format_instructions}"""prompt=_template(template,partial_variables={"format_instructions":output__format_instructions()},)chain=LLMChain(prompt=prompt,llm=OpenAI())output=("bitcoin是什么时候成立的?用英文格式输出时间")3.枚举解析器
_(Enum):RED="red"GREEN="green"BLUE="blue"parser=EnumOutputParser(enum=Colors)
4.自动修复解析器:这类解析器是一种嵌套的形式,如果第一个输出解析器出现错误,就会直接调用另一个一修复错误
定义一个表示演员的数据结构,包括他们的名字和他们出演的电影列表classActor(BaseModel):name:str=Field(description="nameofanactor")他们出演的电影列表使用`Actor`模型初始化解析器parser=PydanticOutputParser(pydantic_object=Actor)使用解析器尝试解析上述数据try:parsed_data=(misformatted)exceptExceptionase:print(f"Error:{e}")(misformatted)
格式错误的原因是因为json文件需要双引号进行标记,但是这里用了单引号,此时利用该解析器进行解析就会出现报错,但是此时可以利用RetryWithErrorOutputParser进行修复错误,则会正常输出不报错。
__parser=_llm(parser=parser,llm=OpenAI(temperature=0))retry__with_prompt(bad_response,prompt_value)
这里的“Parse_with_prompt”:一种方法,它接受一个字符串(假设是来自语言模型的响应)和一个提示(假设是生成此类响应的提示)并将其解析为某种结构。提示主要在OutputParser想要以某种方式重试或修复输出时提供,并且需要来自提示的信息才能执行此操作。
四、RetrievalRetrieval直接汉译过来即”检索“。该功能经常被应用于构建一个“私人的知识库”,构建过程更多的是将外部数据存储到知识库中。细化这一模块的主要职能有四部分,其包括数据的获取、整理、存储和查询。如下图:

首先,在该过程中可以从本地/网站/文件等资源库去获取数据,当数据量较小时,我们可以直接进行存储,但当数据量较大的时候,则需要对其进行一定的切片,切分时可以按照数据类型进行切片处理,比如针对文本类数据,可以直接按照字符、段落进行切片;
代码类数据则需要进一步细分以保证代码的功能性;此外,除了按照数据类型进行切片处理,也可以直接根据token进行切片。而后利用VectorStores进行向量存储,其中Embedding完成的就是数据的向量化,虽然这一能力往往被嵌套至大模型中,但是我们也要清楚并不是所有的模型都能直接支持文本向量化这一能力。除此之外的memory、self-hosted以及baas则是指向量存储的三种载体形式,
可以选择直接存储于内存中,也可以选择存储上云。最后则利用这些向量化数据进行检索,检索形式可以是直接按照向量相似度去匹配相似内容,也可以直接网络,或者借用其他服务实现检索以及数据的返回。
4.1向量数据库4.1.1基本概念从上文中我们可以发现,对于retrievers来说,向量数据库发挥着很大的作用,它不仅实现向量的存储也可以通过相似度实现向量的检索,但是向量数据库到底是什么呢?它和普通的数据库有着怎样的区别呢?相信还是有很多同学和我一样有一点点疑惑,所以在介绍langchain在此module方面的能力前,先介绍一下向量数据库,以及它在LLM中所发挥的作用。
我们在对一个事物进行描述的时候,通常会根据事物的各方面特征进行表述。设想这样一个场景,假设你是一名摄影师,拍了大量的照片。为了方便管理和查找,你决定将这些照片存储到一个数据库中。传统的关系型数据库(如MySQL、PostgreSQL等)可以帮助你存储照片的元数据,比如拍摄时间、地点、相机型号等。但是,当你想要根据照片的内容(如颜色、纹理、物体等)进行搜索时,传统数据库可能无法满足你的需求,因为它们通常以数据表的形式存储数据,并使用查询语句进行精确搜索。但向量包含了大量信息,使用查询语句很难精确地找到唯一的向量。
那么此时,向量数据库就可以派上用场。我们可以构建一个多维的空间使得每张照片特征都存在于这个空间内,并用已有的维度进行表示,比如时间、地点、相机型号、颜色.此照片的信息将作为一个点,存储于其中。以此类推,即可在该空间中构建出无数的点,而后我们将这些点与空间坐标轴的原点相连接,就成为了一条条向量,当这些点变为向量之后,即可利用向量的计算进一步获取更多的信息。当要进行照片的检索时,也会变得更容易更快捷。但在向量数据库中进行检索时,检索并不是唯一的而是查询和目标向量最为相似的一些向量,具有模糊性。
4.1.2存储方式因为每一个向量所记录的信息量都是比较多的,所以自然而然其所占内存也是很大的,举个例子,如果我们的一个向量维度是256维的,那么该向量所占用的内存大小就是:256*32/8=1024字节,若数据库中共计一千万个向量,则所占内存为10240000000字节,也就是9.54GB,已经是一个很庞大的数目了,而在实际开发中这个规模往往更大,因此解决向量数据库的内存占用问题是重中之重的。我们往往会对每个向量进行压缩,从而缩小其内存占用。常常利用乘积量化方法
乘积量化:该思想将高维向量分解为多个子向量。例如,将一个D维向量分解为m个子向量,每个子向量的维度为D/m。然后对每个子向量进行量化。对于每个子向量空间,使用聚类算法将子向量分为K个簇,并将簇中心作为量化值。然后,用子向量在簇中的索引来表示原始子向量。这样,每个子向量可以用一个整数(量化索引)来表示。最后将量化索引组合起来表示原始高维向量。对于一个D维向量,可以用m个整数来表示,其中每个整数对应一个子向量的量化索引。此外这类方法不仅可以用于优化存储向量也可以用于优化检索。
4.1.3检索方式通过上段文字的描述,我们不难发现,向量检索过程可以抽象化为“最近邻问题“,对应的算法就是最近邻搜索算法,具体有如下几种:
1.暴力搜索:依次比较向量数据库中所有的的向量与目标向量的相似度,然后找出相似度最高一个或一些向量,这样得到的结果质量是极高的,但这对于数据量庞大的数据库来说无疑是十分耗时的。
2.聚类搜索:这类算法首先初始化K个聚类中心,将数据对象分组成若干个类别或簇(cluster)。其主要目的是根据数据的相似性或距离度量来对数据进行分组,然后根据所选的聚类算法,通过迭代计算来更新聚类结果。例如,在K-means算法中,需要不断更新簇中心并将数据对象分配给最近的簇中心;在DBSCAN算法中,需要根据密度可达性来扩展簇并合并相邻的簇。最后设置一个收敛条件,用于判断聚类过程是否结束。收敛条件可以是迭代次数、簇中心变化幅度等。当满足收敛条件时,聚类过程结束。这样的搜索效率大大提高,但是不可避免会出现遗漏的情况。
3.位置敏感哈希:此算法首先选择一组位置敏感哈希函数,该函数需要满足一个特性:对于相似的数据点,它们的哈希值发生冲突的概率较高;对于不相似的数据点,它们的哈希值发生冲突的概率较低。而后利用该函数对数据集中的每个数据点进行哈希。将具有相同哈希值的数据点存储在相同的哈希桶中。在检索过程中,对于给定的查询点,首先使用LSH函数计算其哈希值,然后在相应的哈希桶中搜索相似的数据点。最后根据需要,可以在搜索到的候选数据点中进一步计算相似度,以找到最近邻。
4.分层级的导航小世界算法:这是一种基于图的近似最近邻搜索方法,适用于大规模高维数据集。其核心思想是将数据点组织成一个分层结构的图,使得在高层次上可以快速地找到距离查询点较近的候选点,然后在低层次逐步细化搜索范围,从而加速最近邻搜索过程。
该算法首先创建一个空的多层图结构。每一层都是一个图,其中节点表示数据点,边表示节点之间的连接关系。最底层包含所有数据点,而上层图只包含部分数据点。每个数据点被分配一个随机的层数,表示该点在哪些层次的图中出现。然后插入数据点:对于每个新插入的数据点,首先确定其层数,然后从最高层开始,将该点插入到相应的图中。插入过程中,需要找到该点在每层的最近邻,并将它们连接起来。同时,还需要更新已有节点的连接关系,以保持图的导航性能。其检索过程是首先在最高层的图中找到一个起始点,然后逐层向下搜索,直到达到底层。在每一层,从当前点出发,沿着边进行搜索,直到找到一个局部最近邻。然后将局部最近邻作为下一层的起始点,继续搜索。最后,在底层找到的结果则为最终结果。
4.2向量数据库与AI前文中大概介绍了向量数据库是什么以及向量数据库所依赖的一些实现技术,接下来我们来谈论一下向量数据库与大模型之间的关系。为什么说想要用好大模型往往离不开向量数据库呢?对于大模型来讲,处理的数据格式一般都是非结构化数据,如音频、文本、图像..我们以大语言模型为例,在喂一份数据给大模型的时候,数据首先会被转为向量,在上述内容中我们知道如果向量较近那么就表示这两个向量含有的信息更为相似,当大量数据不断被喂到大模型中的时候,语言模型就会逐渐发现词汇间的语义和语法。
当用户进行问答的时候,问题输入Model后会基于Transformer架构从每个词出发去找到它与其他词的关系权重,找到权重最重的一组搭配,这一组就为此次问答的答案了。最后再将这组向量返回回来,也就完成了一次问答。当我们把向量数据库接入到AI中,我们就可以通过更新向量数据库的数据,使得大模型能够不断获取并学习到业界最新的知识,而不是将能力局限于预训练的数据中。这种方式要比微调/重新训练大模型的方式节约更多成本。
4.3DataLoaders为了更好的理解retrieval的功能,在上文中先介绍了一下它所依赖的核心概念——向量数据库,接下来让我们看一下Langhcain中的retrieval是如何发挥作用的。我们已经知道,一般在用户开发(LLM)应用程序,往往会需要使用不在模型训练集中的特定数据去进一步增强大语言模型的能力,这种方法被称为检索增强生成(RAG)。LangChain提供了一整套工具来实现RAG应用程序,首先第一步就是进行文档的相应加载即DocumentLoader:
1.加载md文件:
_loadersimportTextLoader使用load方法加载文件内容并打印print(())
2.加载csv文件:
创建CSVLoader实例,指定要加载的CSV文件路径loader=CSVLoader(file_path='./')创建CSVLoader实例,指定要加载的CSV文件路径和CSV参数loader=CSVLoader(file_path='./',csv_args={'delimiter':',','quotechar':'"','fieldnames':['title','content']})创建CSVLoader实例,指定要加载的CSV文件路径和源列名loader=CSVLoader(file_path='./',source_column="context")导入DirectoryLoader类_loadersimportDirectoryLoader使用load方法加载所有文档并将其存储在docs变量中docs=()导入UnstructuredHTMLLoader类_loadersimportUnstructuredHTMLLoader使用load方法加载HTML文件内容并将其存储在data变量中data=()创建BSHTMLLoader实例,指定要加载的HTML文件路径loader=BSHTMLLoader("./")打开一个文本文件并读取内容withopen('./')asf:state_of_the_union=()创建RecursiveCharacterTextSplitter实例,设置块大小、块重叠、长度函数和是否添加开始索引text_splitter=RecursiveCharacterTextSplitter(chunk_size=100,chunk_overlap=20,length_function=len,add_start_index=True,)导入所需的类和枚举_splitterimportRecursiveCharacterTextSplitter,LanguageCallthefunctionhello_world()"""使用create_documents方法创建文档并将其存储在python_docs变量中python_docs=python__documents([PYTHON_CODE])调用特定的拆分器可以保证拆分后的代码逻辑,这里我们只要指定不同的Language就可以对不同的语言进行拆分。
4.5向量检索简单应用在实际开发中我们可以将数据向量化细分为两步:一是将数据向量化(向量化工具:openai的embeding、huggingface的n3d),二是将向量化后的数据存储到向量数据库中,常见比较好用的免费向量数据库有Meta的faiss、chrome的chromad以及lance。
1.高性能:利用CPU和GPU的并行计算能力,实现了高效的向量索引和查询操作。2.可扩展性:支持大规模数据集,可以处理数十亿个高维向量的相似性搜索和聚类任务。3.灵活性:提供了多种索引和搜索算法,可以根据具体需求选择合适的算法。4.开源:是一个开源项目,可以在GitHub上找到其源代码和详细文档。
安装相关库:pipinstallfaiss-cpu(显卡好的同学也可以installgpu版本)
准备一个数据集,这个数据集包含一段关于信用卡年费收取和提高信用卡额度的咨询对话。客户向客服提出了关于信用卡年费和额度的问题,客服则详细解答了客户的疑问:
text="""客户:您好,我想咨询一下信用卡的问题。\n客服:您好,欢迎咨询建行信用卡,我是客服小李,请问有什么问题我可以帮您解答吗?\n客户:我想了解一下信用卡的年费如何收取?\n客服:关于信用卡年费的收取,我们会在每年的固定日期为您的信用卡收取年费。当然,如果您在一年内的消费达到一定金额,年费会自动免除。具体的免年费标准,请您查看信用卡合同条款或登录我们的网站查询。\n客户:好的,谢谢。那我还想问一下,如何提高信用卡的额度?\n客服:关于提高信用卡额度,您可以通过以下途径操作:1.登录建行信用卡官方网站或手机APP,提交在线提额申请;2.拨打我们的客服热线,按语音提示进行提额申请;3.您还可以前往附近的建行网点,提交提额申请。在您提交申请后,我们会根据您的信用状况进行审核,审核通过后,您的信用卡额度将会相应提高。\n客户:明白了,非常感谢您的解答。\n客服:您太客气了,很高兴能够帮到您。如果您还有其他问题,请随时联系我们。祝您生活愉快!"""list_text=('\n')=_texts(list_text,OpenAIEmbeddings())query="信用卡的额度可以提高吗"docs=_search(query)print(docs[0].page_content)embedding_vector=OpenAIEmbeddings().embed_query(query)print(f'embedding_vector:{embedding_vector}')docs=_search_by_vector(embedding_vector)print(docs[0].page_content)除了上述直接输出效果最好的结果,也可以按照相似度分数进行输出,不过这里的规则是分数越低,相似度越高。
打印文档及其相似性分数fordoc,scoreindocs_and_scores:print(f"Document:{_content}\nScore:{score}\n")如果每次都要调用embedding无疑太浪费,所以最后我们也可以直接将数据库保存起来,避免重复调用。
加载new_db=_local("faiss_index",OpenAIEmbeddings())在官网中还介绍了另外两种向量数据库的使用方法,这里不再赘述。
五、MemoryMemory——存储历史对话信息。该功能主要会执行两步:1.输入时,从记忆组件中查询相关历史信息,拼接历史信息和用户的输入到提示词中传给LLM。2.自动把LLM返回的内容存储到记忆组件,用于下次查询。
5.1Memory的基本实现原理:Memory——存储历史对话信息。该功能主要会执行两步:
1.输入时,从记忆组件中查询相关历史信息,拼接历史信息和用户的输入到提示词中传给LLM。
2.自动把LLM返回的内容存储到记忆组件,用于下次查询。
不过,GPT目前就有这个功能了,它已经可以进行多轮对话了,为何我们还要把这个功能拿出来细说呢?在之前介绍prompt的文章中介绍过:在进行多轮对话时,我们会把历史对话内容不断的push到prompt数组中,通俗来讲就是将所有的聊天记录都作为prompt了,以存储的形式实现了大语言模型的“记忆”功能,而大语言模型本身是无状态的,这种方式无疑会较为浪费token,所以开发者不得不将注意力聚焦于如何在保证大语言模型功能的基础上尽可能的减少token的使用,Memory这个组件也就随之诞生。po一张Memory官网的图:
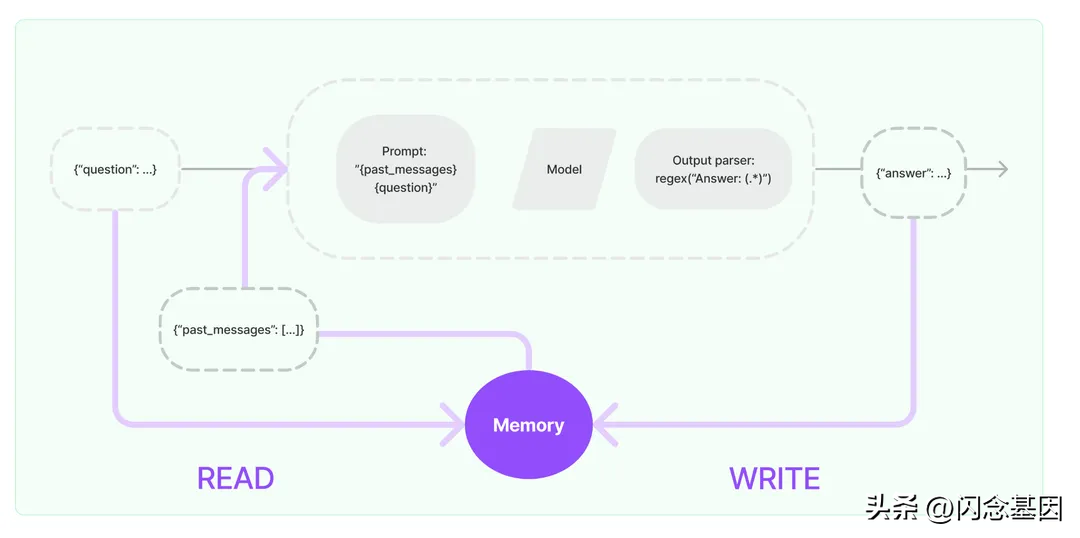
从上图可以看到Memory实现思路还是蛮简单的,就是存储查询,存储的过程我们无需过度思考,无非就是存到内存/数据库,但是读取的过程还是值得我们探讨一番,为什么这么说呢?在上文中已经知道memory的目的其实就是要在保证大语言模型能力的前提下尽可能的减少token消耗,所以我们不能把所有的数据一起丢给大语言模型,这就失去了memory的意义了,不是吗?目前memory常利用以下几种查询策略:
1.将会话直接作为prompt喂回给大模型背景,可以称之为buffer。
2.将所有历史消息丢给模型生成一份摘要,再将摘要作为prompt背景,可以称之为summary。
3.利用之前提及的向量数据库,查询相似历史信息,作为prompt背景,可以称之为vector。
5.2Memory的使用方式:Memory这一功能的使用方式还是较为简单的,本节将会按照memory的三大分类,依次介绍memory中会被高频使用到的一些工具函数。
5.2.1Buffer1️⃣ConversationBufferMemory
先举例一个最简单的使用方法——直接将内容存储到buffer,无论是单次或是多次存储,其对话内容都会被存储到一个memory:
memory=ConversationBufferMemory()_context({"input":"你好,我是人类"},{"output":"你好,我是AI助手"})_context({"input":"很开心认识你"},{"output":"我也是"})存储后可直接输出存储内容:
print(_memory_variables({})){'history':'Human:很开心认识你\nAI:我也是'}通过内置在Langchain中的缓存窗口(BufferWindow)可以将meomory"记忆"下来。
3️⃣ConversationTokenBufferMemory除了通过设置对话数量控制memory,也可以通过设置token来限制。如果字符数量超出指定数目,它会切掉这个对话的早期部分以保留与最近的交流相对应的字符数量
_=ChatOpenAI(temperature=0.0)memory=ConversationTokenBufferMemory(llm=llm,)_context({"input":"春眠不觉晓"},{"output":"处处闻啼鸟"})_context({"input":"夜来风雨声"},{"output":"花落知多少"})print(_memory_variables({}))人类和AI都表示没有做什么特别的事该API通过predict_new_summary成功的将对话进行了摘要总结。
5.2.3vector最后来介绍一下vector在memory中的用法,通过VectorStoreRetrieverMemory可以将memory存储到Vector数据库中,每次调用时,就会查找与该记忆关联最高的k个文档,并且不会跟踪交互顺序。不过要注意的是,在利用VectorStoreRetrieverMemory前,我们需要先初始化一个VectorStore,免费向量数据库有Meta的faiss、chrome的chromad以及lance,以faiss为例:
_size=1536在实际使用中,可以将`k`设为更高的值,这里使用k=1来展示当添加到一个代理时,内存对象可以保存来自对话或使用的工具的相关信息_context({"input":"我最喜欢的食物是披萨"},{"output":"好的,我知道了"})_context({"input":"我最喜欢的运动是足球"},{"output":""})_context({"input":"我不喜欢凯尔特人队"},{"output":"好的"})print(_memory_variables({"prompt":"我应该看什么运动?"})["history"])这时便会根据向量数据库检索后输出memory结果
{'history':[{'input':'我最喜欢的运动是足球','output':''}]}这表示在与用户的对话历史中,语义上与"我应该看什么运动?"最相关的是"我最喜欢的运动是足球"这个对话。更复杂一点可以通过conversationchain进行多轮对话:
llm=OpenAI(temperature=0)我们为测试目的设置了一个非常低的max_token_limit。memory=memory,verbose=True)conversation_with_(input="嗨,我叫Perry,你好吗?")Promptafterformatting:Finishedchain.这里,与篮球相关的内容被提及conversation_with_(input="我最喜欢的运动是什么?")'你之前告诉我你最喜欢的运动是足球。'"为记忆和数据加上时间戳通常是有用的,以便让代理确定时间相关性conversation_with_(input="我的最喜欢的食物是什么?")'你说你最喜欢的食物是披萨。'"由于这个查询与上面的介绍聊天最匹配,输出:"EnteringnewConversationChainchainFinishedchain.输出结果'Socktastic!'6.2SequentialChains:
不同于基本的LLMChain,Sequentialchain(序列链)是由一系列的链组合而成的,序列链有两种类型,一种是单个输入输出/另一个则是多个输入输出。先来看第一种单个输入输出的示例代码:
1.单个输入输出第一条chain:
,OpenAI,LLMChainllm=OpenAI(temperature=.7)template=""",:{synopsis}ReviewfromaNewYorkTimesplaycriticoftheaboveplay:"""prompt_template=PromptTemplate(input_variables=["synopsis"],template=template)review_chain=LLMChain(llm=llm,prompt=prompt_template)最后利用SimpleSequentialChain即可将两个chain直接串联起来:
_chain=SimpleSequentialChain(chains=[synopsis_chain,review_chain],verbose=True)print(review=overall_("Tragedyatsunsetonthebeach"))可以看到对于单个输入输出的顺序链,就是将两个chain作为参数传给simplesequentialchain即可,无需复杂的声明。
2.多个输入输出fromlangchainimportPromptTemplate,OpenAI,LLMChainllm=OpenAI(temperature=.7)template=""",:{title}Era:{era}Playwright:Thisisasynopsisfortheaboveplay:"""prompt_template=PromptTemplate(input_variables=["title",'era'],template=template)synopsis_chain=LLMChain(llm=llm,prompt=prompt_template,output_key="synopsis")第二条chain_chain=SequentialChain(chains=[synopsis_chain,review_chain],input_variables=["era","title"],第三条chain
overall_chain({"title":"Tragedyatsunsetonthebeach","era":"VictorianEngland"})6.3RouterChains:最后介绍一个经常会用到的场景,比如我们目前有三类chain,分别对应三种学科的问题解答。我们的输入内容也是与这三种学科对应,但是随机的,比如第一次输入数学问题、第二次有可能是历史问题这时候期待的效果是:可以根据输入的内容是什么,自动将其应用到对应的子链中。RouterChain就为我们提供了这样一种能力,它会首先决定将要传递下去的子链,然后把输入传递给那个链。并且在设置的时候需要注意为其设置默认chain,以兼容输入内容不满足任意一项时的情况。
physics_template="""Youareaverysmartphysicsprofessor.\Youaregreatatansweringquestionsaboutphysicsinaconciseandeasytounderstandmanner.\Whenyoudon'tknowtheanswertoaquestionyouadmitthatyoudon':{input}"""math_template="""\Youaresogoodbecauseyouareabletobreakdownhardproblemsintotheircomponentparts,\answerthecomponentparts,:{input}"""如上有一个物理学和数学的prompt:
prompt_infos=[{"name":"physics","description":"Goodforansweringquestionsaboutphysics","prompt_template":physics_template},{"name":"math","description":"Goodforansweringmathquestions","prompt_template":math_template}]然后,需要声明这两个prompt的基本信息。
fromlangchainimportConversationChain,LLMChain,PromptTemplate,OpenAIllm=OpenAI()destination_chains={}forp_infoinprompt_infos:name=p_info["name"]prompt_template=p_info["prompt_template"]prompt=PromptTemplate(template=prompt_template,input_variables=["input"])chain=LLMChain(llm=llm,prompt=prompt)destination_chains[name]=chaindefault_chain=ConversationChain(llm=llm,output_key="text")最后将其运行到routerchain中即可,我们此时在输入的时候chain就会根据input的内容进行相应的选择最为合适的prompt。
_routerimportLLMRouterChain,_prompt_promptimportMULTI_PROMPT_ROUTER_TEMPLATECreatearoutertemplaterouter_template=MULTI_PROMPT_ROUTER_(destinations=destinations_str)router_prompt=PromptTemplate(template=router_template,input_variables=["input"],output_parser=RouterOutputParser(),)router_chain=_llm(llm,router_prompt)chain=MultiPromptChain(router_chain=router_chain,destination_chains=destination_chains,default_chain=default_chain,verbose=True,)print(('什么是黑体辐射'))七、AgentsAgents这一模块在langchain的使用过程中也是十分重要的,官方文档是这样定义它的“Thecoreid,asequenceofactionsishardcoded(incode).Inagents,alanguagemodelisusedasareasoningenginetodeterminewhichactionstotakeandinwhichorder.”也就是说,在使用Agents时,其行为以及行为的顺序是由LLM的推理机制决定的,并不是像传统的程序一样,由核心代码预定义好去运行的。
举一个例子来对比一下,对于传统的程序,我们可以想象这样一个场景:一个王子需要经历3个关卡,才可以救到公主,那么王子就必须按部就班的走一条确定的路线,一步步去完成这三关,才可以救到公主,他不可以跳过或者修改关卡本身。但对于Agents来说,我们可以将其想象成一个刚出生的原始人类,随着大脑的日渐成熟和身体的不断发育,该人类将会逐步拥有决策能力和记忆能力,这时想象该人类处于一种饥饿状态,那么他就需要吃饭。此时,他刚好走到小河边,通过“记忆”模块,认知到河里的“鱼”是可以作为食物的,那么他此时就会巧妙的利用自己身边的工具——鱼钩,进行钓鱼,然后再利用火,将鱼烤熟。
第二天,他又饿了,这时他在丛林里散步,遇到了一头野猪,通过“记忆”模块,认知到“野猪”也是可以作为食物的,由于野猪的体型较大,于是他选取了更具杀伤力的长矛进行狩猎。从他这两次狩猎的经历,我们可以发现,他并不是按照预先设定好的流程,使用固定的工具去捕固定的猎物,而是根据环境的变化选择合适的猎物,又根据猎物的种类,去决策使用的狩猎工具。这一过程完美的利用了自己的决策、记忆系统,并辅助利用工具,从而做出一系列反应去解决问题。以一个数学公式来表示,可以说Agents=LLM(决策)+Memory(记忆)+Tools(执行)。
通过上述的例子,相信你已经清楚的认知到Agents与传统程序比起来,其更加灵活,通过不同的搭配,往往会达到令人意想不到的效果,现在就用代码来实操感受一下Agents的实际应用方式,下文的示例代码主要实现的功能是——给予Agent一个题目,让Agent生成一篇论文。
配置工具集llm,设置agent类型agent_kwargs=agent_kwargs,配置记忆模式)7.1tools相关的配置介绍
首先是配置工具集tools,如下列代码,可以看到这是一个二元数组,也就意味着本示例中的Agents依赖两个工具。
_agent,Tooltools=[Tool(name="Search",func=search,description="usefulforwhenyouneedtoanswerquestionsaboutcurrentevents,"),ScrapeWebsiteTool(),]
先看第一个工具:在配置工具时,需要声明工具依赖的函数,由于该示例实现的功能为依赖网络收集相应的信息,然后汇总成一篇论文,所以创建了一个search函数,这个函数用于调用Google搜索。它接受一个查询参数,然后将查询发送给SerperAPI。API的响应会被打印出来并返回。
根据url爬取网页内容,给出最终解答url:Agent在完成以上目标时所需要的URL,完全由Agent自主决定并且选取,其内容或是中间步骤需要,或是最终解答需要defscrape_website(target:str,url:str):print(f"开始爬取:{url}")headers={'Cache-Control':'no-cache','Content-Type':'application/json',}payload=({"url":url})post_url=f"{browserless_api_key}"response=(post_url,headers=headers,data=payload)控制返回内容长度,如果内容太长就需要切片分别总结处理iflen(text)5000:如果需要处理的内容过长,先切片分别处理,再综合总结modellist:(temperature=0,model="")chunk_overlap是一个在使用OpenAI的GPT-3或GPT-4API时可能会遇到的参数,特别是需要处理长文本时。上下文维护:重叠确保模型在处理后续块时有足够的上下文信息。初始化大语言模型,负责决策llm=ChatOpenAI(temperature=0,model="")这段代码初始化了一个名为llm的大语言模型对象,它是ChatOpenAI类的实例。ChatOpenAI类用于与大语言模型(如GPT-3)进行交互,以生成决策和回答。在初始化ChatOpenAI对象时,提供了以下参数:
1.temperature:一个浮点数,表示生成文本时的温度。温度值越高,生成的文本将越随机和多样;温度值越低,生成的文本将越确定和一致。在这里设置为0,因为本demo的目的为生成一个论文,所以我们并不希望大模型有较多的可变性,而是希望生成非常确定和一致的回答。2.model:一个字符串,表示要使用的大语言模型的名称。在这里,我们设置为"",表示使用模型。
7.3Agent类型及角色相关的配置介绍首先来看一下AgentType这个变量的初始化,这里是用来设置agent类型的一个参数,具体可以参考官网:AgentType
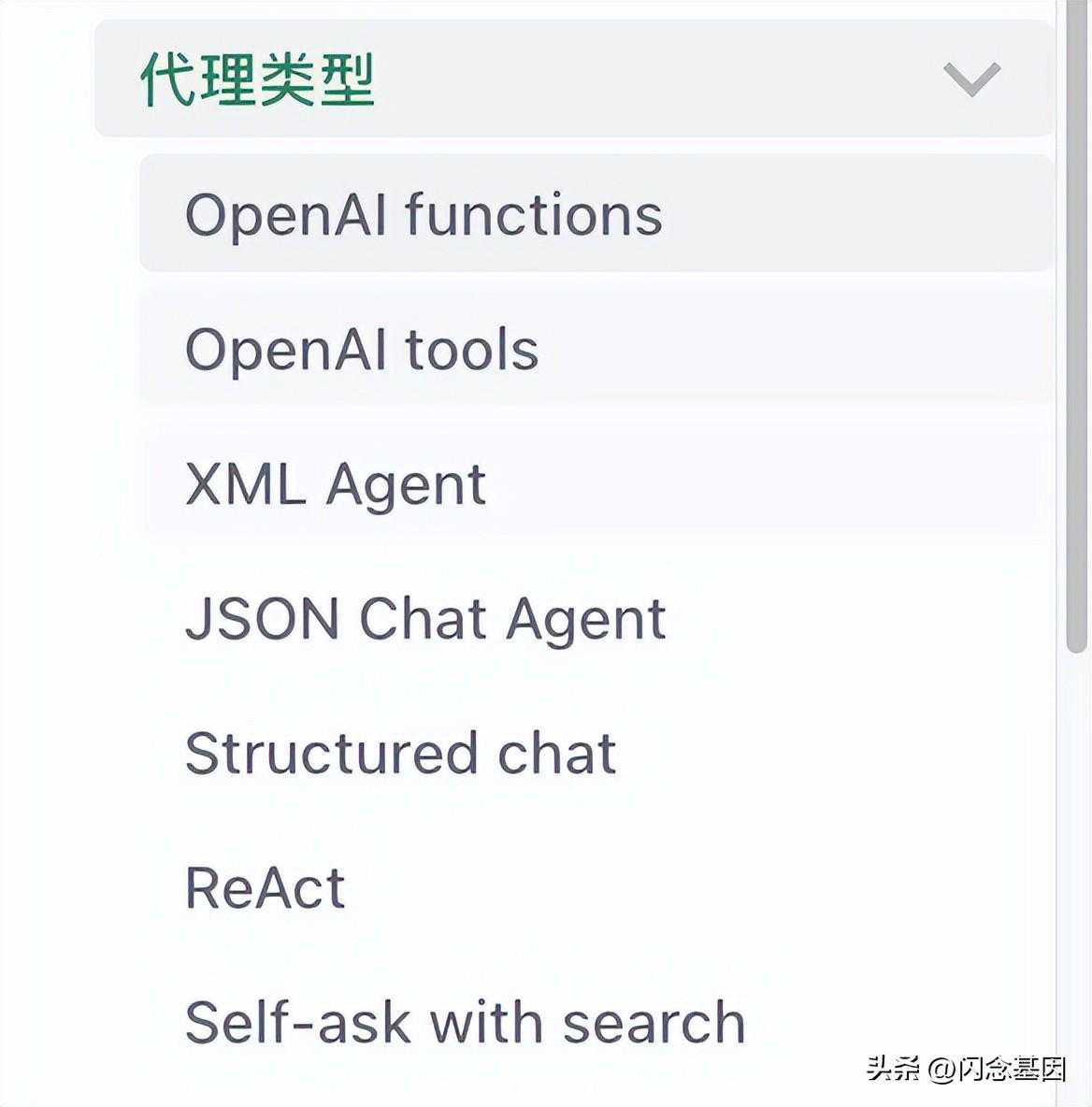
可以看到官网里列举了7中agent类型,可以根据自己的需求进行选择,在本示例中选用的是第一种类型OpenAifunctions。此外,还要设定agent角色以及记忆模式:
初始化agent角色模板agent_kwargs={"extra_prompt_messages":[MessagesPlaceholder(variable_name="memory")],"system_message":system_message,}初始化记忆类型memory=ConversationSummaryBufferMemory(memory_key="memory",return_messages=True,llm=llm,max_token_limit=300)在设置memory的记忆类型对象时:利用了ConversationSummaryBufferMemory类的实例。该类用于在与AI助手的对话中缓存和管理信息。在初始化这个对象时,提供了以下参数:1.memory_key:一个字符串,表示这个记忆对象的键。在这里设置为"memory"。2.return_messages:一个布尔值,表示是否在返回的消息中包含记忆内容。在这里设置为True,表示希望在返回的消息中包含记忆内容。3.llm:对应的大语言模型对象,这里是之前初始化的llm对象。这个参数用于指定在处理记忆内容时使用的大语言模型。4。max_token_limit:一个整数,表示记忆缓存的最大令牌限制。在这里设置为300,表示希望缓存的记忆内容最多包含300个token。
7.5依赖的环境包倒入以及启动主函数这里导入所需库:这段代码导入了一系列所需的库,包括os、dotenv、langchain相关库、requests、BeautifulSoup、json和streamlit。
importosfromdotenvimportload__agent,___summarize_,ifulSoupimportrequestsimportjsonimportstreamlitasst#加载必要的参数load_dotenv()serper_api_key=("SERPER_API_KEY")browserless_api_key=("BROWSERLESS_API_KEY")openai_api_key=("OPENAI_API_KEY")main函数:这是streamlit应用的主函数。它首先设置了页面的标题和图标,然后创建了一些header,并提供一个文本输入框让用户输入查询。当用户输入查询后,它会调用agent来处理这个查询,并将结果显示在页面上。
defmain():_page_config(page_title="AIAssistantAgent",page_icon=":dolphin:")("LangChain实例讲解3--Agent",divider='rainbow')("AIAgent:blue[助理]:dolphin:")query=_input("请提问题和需求:")ifquery:(f"开始收集和总结资料【{query}】请稍等")result=agent({"input":query})(result['output'])至此Agent的使用示例代码就描述完毕了,我们可以看到,其实Agents的功能就是其会自主的去选择并利用最合适的工具,从而解决问题,我们提供的Tools越丰富,则其功能越强大。
八、CallbacksCallbacks对于程序员们应该都不陌生,就是一个回调函数,这个函数允许我们在LLM的各个阶段使用各种各样的“钩子”,从而达实现日志的记录、监控以及流式传输等功能。在Langchain中,该回掉函数是通过继承BaseCallbackHandler来实现的,该接口对于每一个订阅事件都声明了一个回掉函数。它的子类也就可以通过继承它实现事件的处理。如官网所示:
classBaseCallbackHandler:"""Basecallbackhandlerthatcanbeusedtohandlecallbacksfromlangchain."""defon_llm_start(self,serialized:Dict[str,Any],prompts:List[str],**kwargs:Any)-Any:"""RunwhenLLMstartsrunning."""defon_chat_model_start(self,serialized:Dict[str,Any],messages:List[List[BaseMessage]],**kwargs:Any)-Any:"""RunwhenChatModelstartsrunning."""defon_llm_new_token(self,token:str,**kwargs:Any)-Any:""""""defon_llm_(self,response:LLMResult,**kwargs:Any)-Any:"""RunwhenLLMsrunning."""defon_llm_error(self,error:Union[Exception,KeyboardInterrupt],**kwargs:Any)-Any:"""RunwhenLLMerrors."""defon_chain_start(self,serialized:Dict[str,Any],inputs:Dict[str,Any],**kwargs:Any)-Any:"""Runwhenchainstartsrunning."""defon_chain_(self,outputs:Dict[str,Any],**kwargs:Any)-Any:"""Runwhenchainsrunning."""defon_chain_error(self,error:Union[Exception,KeyboardInterrupt],**kwargs:Any)-Any:"""Runwhenchainerrors."""defon_tool_start(self,serialized:Dict[str,Any],input_str:str,**kwargs:Any)-Any:"""Runwhentoolstartsrunning."""defon_tool_(self,output:str,**kwargs:Any)-Any:"""Runwhentoolsrunning."""defon_tool_error(self,error:Union[Exception,KeyboardInterrupt],**kwargs:Any)-Any:"""Runwhentoolerrors."""defon_text(self,text:str,**kwargs:Any)-Any:"""Runonarbitrarytext."""defon_agent_action(self,action:AgentAction,**kwargs:Any)-Any:"""Runonagentaction."""defon_agent_finish(self,finish:AgentFinish,**kwargs:Any)-Any:"""Runonagent."""
这个类包含了一系列方法,这些方法在langchain的不同阶段被调用,以便在处理过程中执行自定义操作。参考源码BaseCallbackHandler:
on_llm_start:当大语言模型(LLM)开始运行时调用。on_chat_model_start:当聊天模型开始运行时调用。on_llm_new_token:当有新的LLM令牌时调用。仅在启用流式处理时可用。on_llm_:当LLM运行结束时调用。on_llm_error:当LLM出现错误时调用。on_chain_start:当链开始运行时调用。on_chain_:当链运行结束时调用。on_chain_error:当链出现错误时调用。on_tool_start:当工具开始运行时调用。on_tool_:当工具运行结束时调用。on_tool_error:当工具出现错误时调用。on_text:当处理任意文本时调用。on_agent_action:当代理执行操作时调用。on_agent_finish:当代理结束时调用。
8.1基础使用方式StdOutCallbackHandlerStdOutCallbackHandler是LangChain支持的最基本的处理器,它继承自BaseCallbackHandler。这个处理器将所有回调信息打印到标准输出,对于调试非常有用。以下是如何使用StdOutCallbackHandler的示例:
=StdOutCallbackHandler()llm=OpenAI()prompt=_template("Whois{name}?")chain=LLMChain(llm=llm,prompt=prompt,callbacks=[handler])(name="SuperMario")在这个示例中,我们首先从模块导入了StdOutCallbackHandler类。然后,创建了一个StdOutCallbackHandler实例,并将其赋值给变量handler。接下来,导入了LLMChain、OpenAI和PromptTemplate类,并创建了相应的实例。在创建LLMChain实例时,将callbacks参数设置为一个包含handler的列表。这样,当链运行时,所有的回调信息都会被打印到标准输出。最后,使用()方法运行链,并传入参数name="SuperMario"。在链运行过程中,所有的回调信息将被StdOutCallbackHandler处理并打印到标准输出。
8.2自定义回调处理器(BaseCallbackHandler):def__init__(self)-None:super().__init__()_ms==[]defcurrent_ms(self):returnint(()*1000+_counter()%1*1000)defon_chain_start(self,serialized,inputs,**kwargs)-None:_ms=_ms()defon_chain_(self,outputs,**kwargs)-None:_ms:duration=_ms()-_(duration)defon_llm_start(self,serialized,prompts,**kwargs)-None:_ms=_ms()defon_llm_(self,response,**kwargs)-None:_ms:duration=_ms()-_(duration)llm=OpenAI()timerHandler=TimerHandler()prompt=_template("WhatistheHEXcodeofcolor{color_name}?")chain=LLMChain(llm=llm,prompt=prompt,callbacks=[timerHandler])response=(color_name="blue")print(response)response=(color_name="purple")print(response)这个示例展示了如何通过继承BaseCallbackHandler来实现自定义的回调处理器。在这个例子中,创建了一个名为TimerHandler的自定义处理器,它用于跟踪Chain或LLM交互的起止时间,并统计每次交互的处理耗时。从模块导入BaseCallbackHandler类。导入time模块,用于处理时间相关操作。
定义TimerHandler类,继承自BaseCallbackHandler。在TimerHandler类的init方法中,初始化previous_ms和durations属性。定义current_ms方法,用于返回当前时间的毫秒值。重写on_chain_start、on_chain_、on_llm_start和on_llm_方法,在这些方法中记录开始和结束时间,并计算处理耗时。接下来,我们创建了一个OpenAI实例、一个TimerHandler实例以及一个PromptTemplate实例。然后,我们创建了一个使用timerHandler作为回调处理器的LLMChain实例。最后,我们运行了两次Chain,分别查询蓝色和紫色的十六进制代码。在链运行过程中,TimerHandler将记录每次交互的处理耗时,并将其添加到durations列表中。
输出如下:
8.3callbacks使用场景总结1️⃣通过构造函数参数callbacks设置。这种方式可以在创建对象时就设置好回调处理器。例如,在创建LLMChain或OpenAI对象时,可以通过callbacks参数设置回调处理器。
timerHandler=TimerHandler()llm=OpenAI(callbacks=[timerHandler])response=("WhatistheHEXcodeofcolorBLACK?")print(response)在这里构建llm的时候我们就直接指定了构造函数。
2️⃣通过运行时的函数调用。这种方式可以在运行时动态设置回调处理器,如在Langchain的各module如Model,Agent,Tool,以及Chain的请求执行函数设置回调处理器。例如,在调用LLMChain的run方法或OpenAI的predict方法时,可以通过callbacks参数设置回调处理器。以OpenAI的predict方法为例:
timerHandler=TimerHandler()llm=OpenAI()response=("WhatistheHEXcodeofcolorBLACK?",callbacks=[timerHandler])print(response)这段代码首先创建一个TimerHandler实例并将其赋值给变量timerHandler。然后创建一个OpenAI实例并将其赋值给变量llm。调用()方法,传入问题"WhatistheHEXcodeofcolorBLACK?",并通过callbacks参数设置回调处理器timerHandler。
两种方法的主要区别在于何时和如何设置回调处理器。
构造函数参数callbacks设置:在创建对象(如OpenAI或LLMChain)时,就通过构造函数的callbacks参数设置回调处理器。这种方式的优点是你可以在对象创建时就确定回调处理器,后续在使用该对象时,无需再次设置。但如果在后续的使用过程中需要改变回调处理器,可能需要重新创建对象。
通过运行时的函数调用:在调用对象的某个方法(如OpenAI的predict方法或LLMChain的run方法)时,通过该方法的callbacks参数设置回调处理器。这种方式的优点是你可以在每次调用方法时动态地设置回调处理器,更加灵活。但每次调用方法时都需要设置,如果忘记设置可能会导致回调处理器不生效。
在实际使用中,可以根据需要选择合适的方式。如果回调处理器在对象的整个生命周期中都不会变,可以选择在构造函数中设置;如果回调处理器需要动态变化,可以选择在运行时的函数调用中设置。
九、总结至此,Langchain的各个模块使用方法就已经介绍完毕啦,相信你已经感受到Langchain的能力了~不难发现,LangChain是一个功能十分强大的AI语言处理框架,它将ModelIO、Retrieval、Memory、Chains、Agents和Callbacks这六个模块组合在一起。ModelIO负责处理AI模型的输入和输出,Retrieval模块实现了与向量数据库相关的检索功能,Memory模块则负责在对话过程中存储和重新加载历史对话记录。
Chains模块充当了一个连接器的角色,将前面提到的模块连接起来以实现更丰富的功能。Agents模块通过理解用户输入来自主调用相关工具,使得应用更加智能化。而Callbacks模块则提供了回调机制,方便开发者追踪调用链路和记录日志,以便更好地调试LLM模型。总之,LangChain是一个功能丰富、易于使用的AI语言处理框架,它可以帮助开发者快速搭建和优化AI应用。本文只是列举了各模块的核心使用方法和一些示例demo,建议结合本文认真阅读一遍官方文档会更加有所受益~
作者:qianyuqu
出处:





