作者|TirthajyotiSarkar
译者|清儿爸
编辑|夕颜
在数据科学领域中,具有管道特性的软件包有R语言的dplyr和Python生态系统中的Scikit-learn。
要了解它们在机器学习工作流中的应用,你可以读这篇很棒的文章:
Pandas还提供了`.pipe`方法,可用于类似的用户定义函数。但是,在本文中,我们将讨论的是非常棒的小库,叫pdpipe,它专门解决了PandasDataFrame的管道问题。
使用Pandas的流水线JupyterNotebook的示例可以在我的Github仓库中找到:
。
让我们看看如果使用这个库来构建有用的管道。
数据集
为了演示,我将使用美国房价的数据集,可从Kaggle下载:
我们可以在Pandas中加载数据集,并显示其汇总的统计信息,如下所示:

但是,数据集中还有一个“Address”字段,其中包含了文本数据。
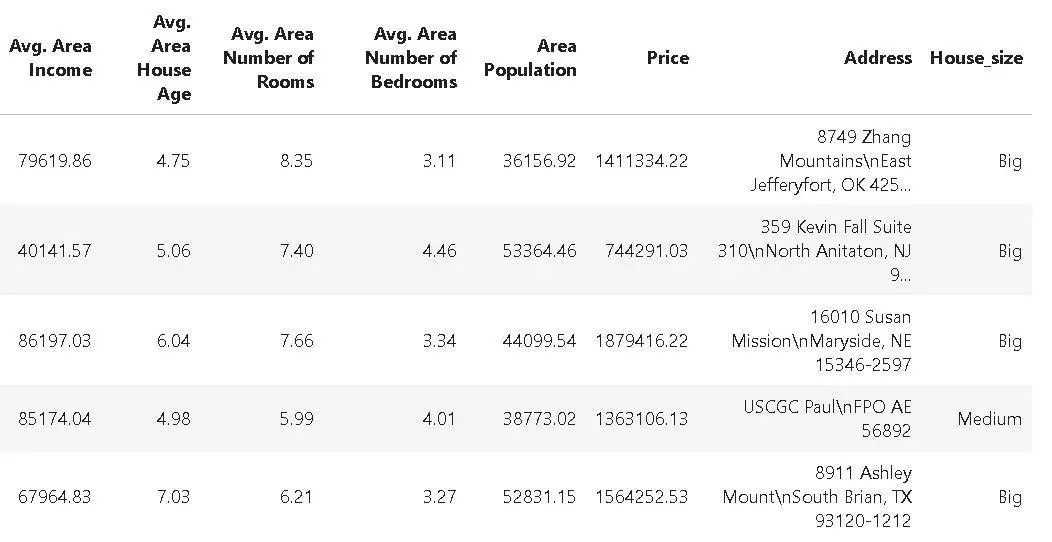
添加大小限定符列
在这个演示中,我们在数据集中添加了一个列来限定房屋的大小,代码如下所示:

经过此步骤之后,数据集如下所示:
我们从最简单的管道开始,它只包含一次操作(不必担心,我们很快就会增加复杂性的)。
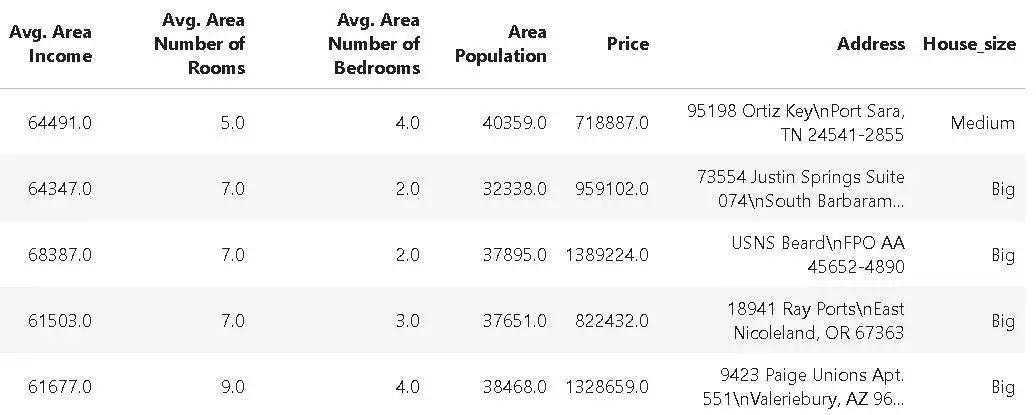
让我们假设机器学习团队和领域专家说他们认为我们可以安全地忽略用于建模的数据``。因此,我们将从数据集中删除这一列。
对于这个任务,我们使用pdpipe中的`ColDrop`来创建一个管道对象`drop_age`,并将DataFrame传递给这个管道。
importpdpipeaspdpdrop_age=(‘’)df2=drop_age(df)
正如预期的那样,生成的DataFrame如下所示:
只需添加管道链级
只有当我们能够进行多个阶段时,管道才是有用和实用的。在pdpipe中有多种方法可以实现这一点。但是,最简单、最直观的方法是使用+运算符。这就像手工连接管道一样!
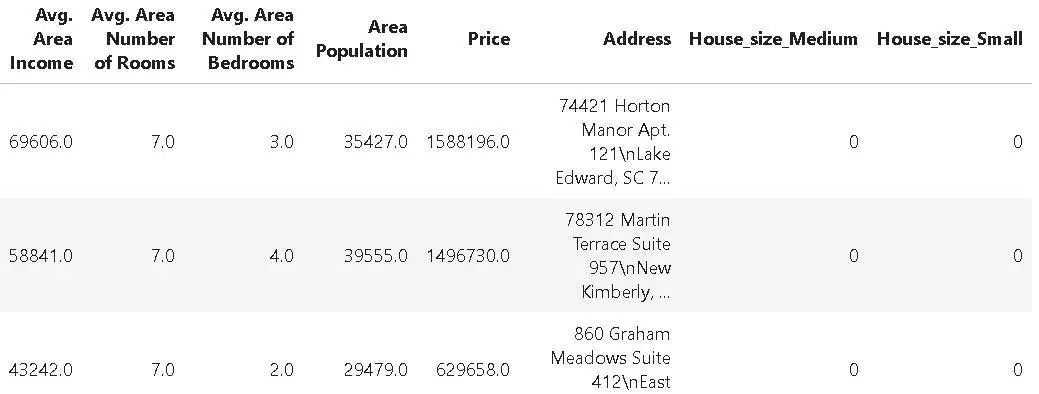
比方说,除了删除`age`列之外,我们还希望对`Housesize`的列进行独热编码,以便可以轻松地在数据集上运行分类或回归算法。
pipeline=(‘’)pipeline+=(‘House_size’)df3=pipeline(df)
因此,我们首先使用`ColDrop`方法创建了一个管道对象来删除``列。此后,我们只需使用常用的Python的`+=`语法将`OneHotEncode`方法添加到这个管道对象中即可。
生成的DataFrame如下所示。请注意,附加的指示列`House_size_Medium`和`House_size_Small`是由独热编码创建的。
接下来,我们可能希望根据行值来删除它们。具体来说,我们可能希望删除房价低于25万的所有数据。我们有`ApplybyCol`的方法来讲删除用户蒂尼的函数应用到DataFrame,还有一个方法`ValDrop`根据特定值来删除某些行。我们可以轻松地将这些方法链接到管道,以便能够有选择地删除行(我们仍在向现有的管道对象中添加内容,该对象已经完成了列删除和独热编码的其他工作)。
defprice_tag(x):ifx250000:return'keep'else:return'drop'pipeline+=('Price',price_tag,'Price_tag',drop=False)pipeline+=(['drop'],'Price_tag')pipeline+=('Price_tag')第一个方法是通过应用用户定义的函数`price_tag()`,根据`Price`列中的值来对行进行标记。
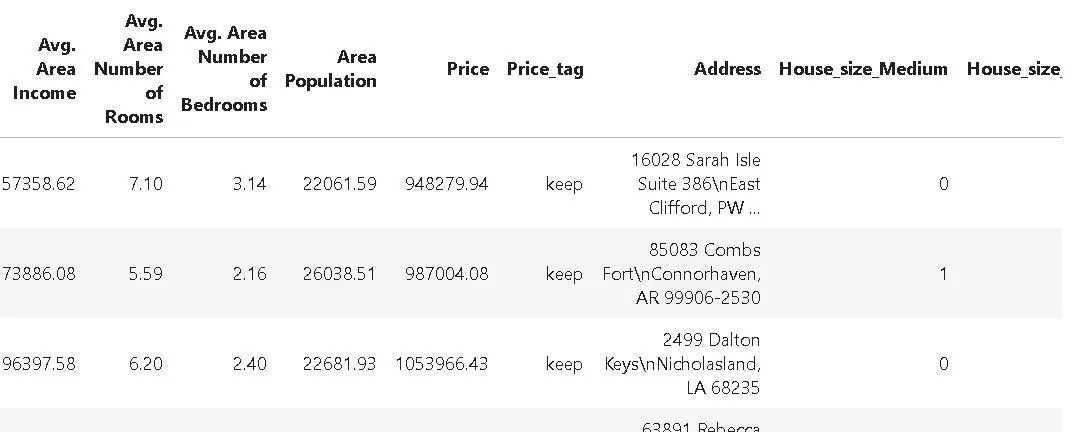
第二种方法是,在`Price_tag`中查找字符串`drop`,并删除那些匹配的行。最后,第三个方法就是删除`Price_tag`标签列,清理DataFrame。毕竟,这个`Price_tag`列只是临时需要的,用于标记特定的行,在达到目的后就应该将其删除。
所有这些都是通过简单地链接同一管道上的各个阶段来完成的!
现在,我们可以回顾一下,看看我们的管道从一开始对DataFrame都做了什么工作:
删除特定的列。
独热编码,用于建模的分类数据列。
根据用户定义函数对数据进行标记。
根据标记删除行。
删除临时标记列。
所有这些,使用的是以下五行代码:
pipeline=('')pipeline+=('House_size')pipeline+=('Price',price_tag,'Price_tag',drop=False)pipeline+=(['drop'],'Price_tag')pipeline+=('Price_tag')df5=pipeline(df)最近版本更新:直接删除行!我与包作者ShayPalachy进行了精彩的讨论,他告诉我,该包的最新版本可以用lambda函数,仅用一行代码即可完成行的删除(满足给定的条件),如下所示:
({‘Price’:lambdax:x=250000})Scikit-learn与NLTK还有许多更有用、更直观的DataFrame操作方法可用于DataFrame操作。但是,我们只是想说明,即使是Scikit-learn和NLTK包中的一些操作,也包含在pdpipe中,用于创建非常出色的管道。
Scikit-learn的缩放估算器建立机器学习模型最常见的任务之一是数据的缩放。Scikit-learn提供了集中不同类型的缩放,例如,最小最大缩放,或者基于标准化的缩放(其中,数据集的平均值被减去,然后除以标准差)。
我们可以在管道中直接链接这些缩放操作。下面的代码段演示了这种用法:
pipeline_scale=('StandardScaler',exclude_columns=['House_size_Medium','House_size_Small'])df6=pipeline_scale(df5)本文中,我们应用了Scikit-learn包中的`StandardScaler`估算器来转换数据以进行聚类或神经网络拟合。我们可以选择性地排除那些无需缩放的列,就像我们在本文中对指示列`House_size_Medium`和`House_size_Small`所做的那样。
瞧!我们得到了缩放后的DataFrame:

NLTK的词法分析器
我们注意到,DataFrame中的Address字段现在几乎毫无用处。但是,如果我们可以从这些字符串中提取邮政编码或州名,它们可能对某种形式的可视化或机器学习任务有用。
为此,我们可以使用WordTokenizer(单词标记器)来实现这一目的。NTLK是一个流行而强大的Python库,用于文本挖掘和自然语言处理,并提供了一系列的标记器方法。在本文示例中,我们客户使用一个这样的标记器来拆分Address字段中的文本,并从中提取州名。我们注意到,州名就是地址字符串中的倒数第二个单词。因此,下面的链式管道就可以帮我们完成这项工作:
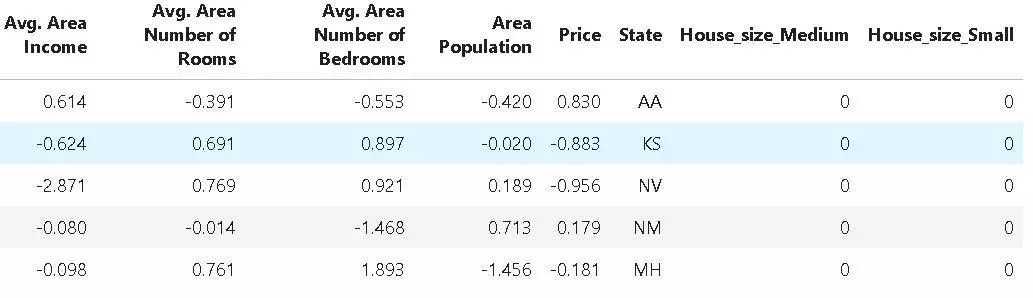
defextract_state(token):returnstr(token[-2])pipeline_tokenize=('Address')pipeline_state=('Address',extract_state,result_columns='State')pipeline_state_extract=pipeline_tokenize+pipeline_statedf7=pipeline_state_extract(df6生成的DataFrame如下所示:
总结
如果我们对本文这个演示中显示的所有操作进行总结,则如下所示:
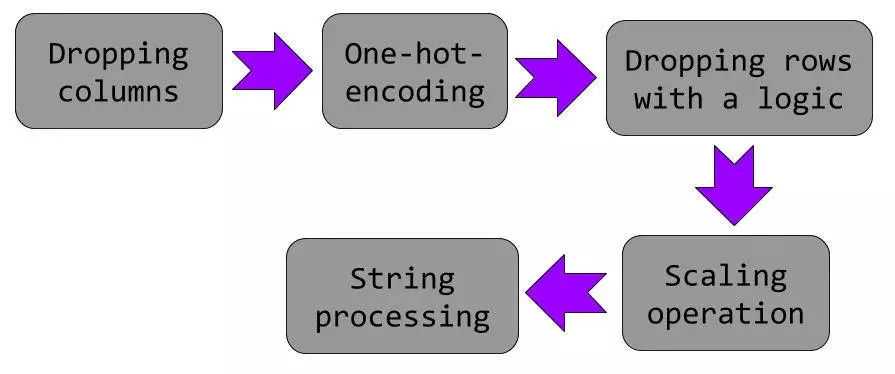
所有这些操作都可以在类似类型的数据集上频繁使用,并在数据集准备好进入下一级建模之前,能有一组简单的顺序代码块作为预处理操作来执行,将是非常棒的。
流水线是实现统一的顺序代码块集的关键。Pandas是机器学习和数据科学团队中用于这类数据预处理任务的最广泛使用的Python库,而pdpipe则提供了一种简单而强大的方法,可以使用Pandas类型操作构建管道,可以直接应用于PandasDataFrame对象。
你可以自己探索这个库,为你的特定数据科学任务构建更强大的管道。





")