就说Sora有多火吧。

作者小哥新上传的效果,点赞很快破千。

失败案例都让人看得上瘾。
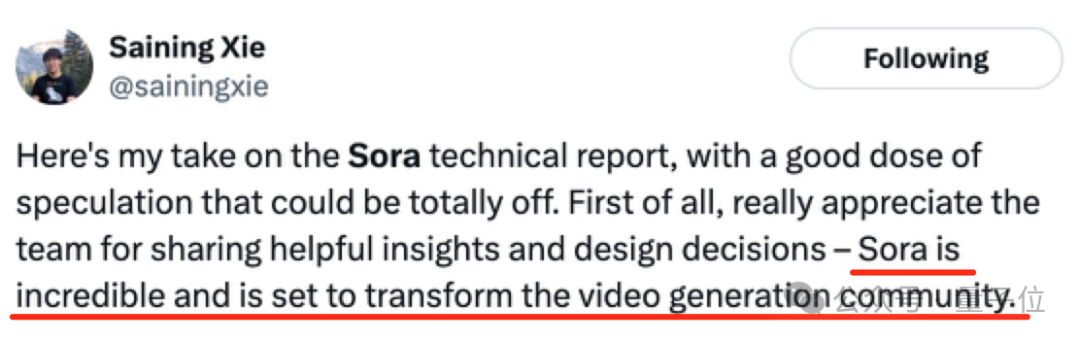

学术圈更炸开锅了,各路大佬纷纷开麦。

尤其在技术报告发布后,讨论变得更加有趣。因为其中诸多细节不是十分明确,所以大佬们也只能猜测。
包括“Sora是一个数据驱动的物理引擎”、“Sora建立在DiT模型之上、参数可能仅30亿”等等。

关于技术细节,官方报告简单提了以下6点:
一是视觉数据的“创新转化”。
与大语言模型中的token不同,Sora采用的是“Patches(补片)”来统一不同的视觉数据表现形式。

Sora就在这上面完成训练。相应地,OpenAI也训练了一个专门的解码器。
三是时空补片技术(Spacetimelatentpatches)。
下图展示出随着训练资源的增加,样本质量明显提升(固定种子和输入条件)。



最后,是语言理解方面上的功夫。
这一系列使得Sora的文字理解能力也相当给力。

可以看到,诸如其中的“patch”到底是怎么设计的等核心问题,文中并没有详细讲解。
有网友吐槽,OpenAI果然还是这么地“Close”(狗头)。
正是如此,各路大佬和网友们的猜测也是五花八门。
谢赛宁分析:
1、Sora应该是建立在DiT这个扩散Transformer之上的。
简而言之,DiT是一个带有Transformer主干的扩散模型,它=[VAE编码器+ViT+DDPM+VAE解码器]。
谢赛宁猜测,在这上面,Sora应该没有整太多花哨的额外东西。
而由于VAE是一个ConvNet,所以DiT从技术上来说是一个混合模型。

3、Sora可能有大约30亿个参数。
谢赛宁认为这个推测不算不合理,因Sora可能还真并不需要人们想象中的那么多GPU来训练,如果真是如此,Sora的后期迭代也将会非常快。
英伟达AI科学家JimFan则认为:
Sora应该是一个数据驱动的物理引擎。
JimFan分析,Sora首先要提供两个3D资产:不同装饰的海盗船;必须在潜在空间中解决text-to-3D的隐式问题;并且要两艘船避开彼此的路线,兼顾咖啡液体的流体力学、保持真实感、带来仿佛光追般的效果。
有一些观点认为,Sora只是在2D层面上控制像素。JimFan明确反对这种说法。他觉得这就像说GPT-4不懂编码,只是对字符串进行采样。
不过他也表示,Sora还无法取代游戏引擎开发者,因为它对于物理的理解还远远不够,仍然存在非常严重的“幻觉”。


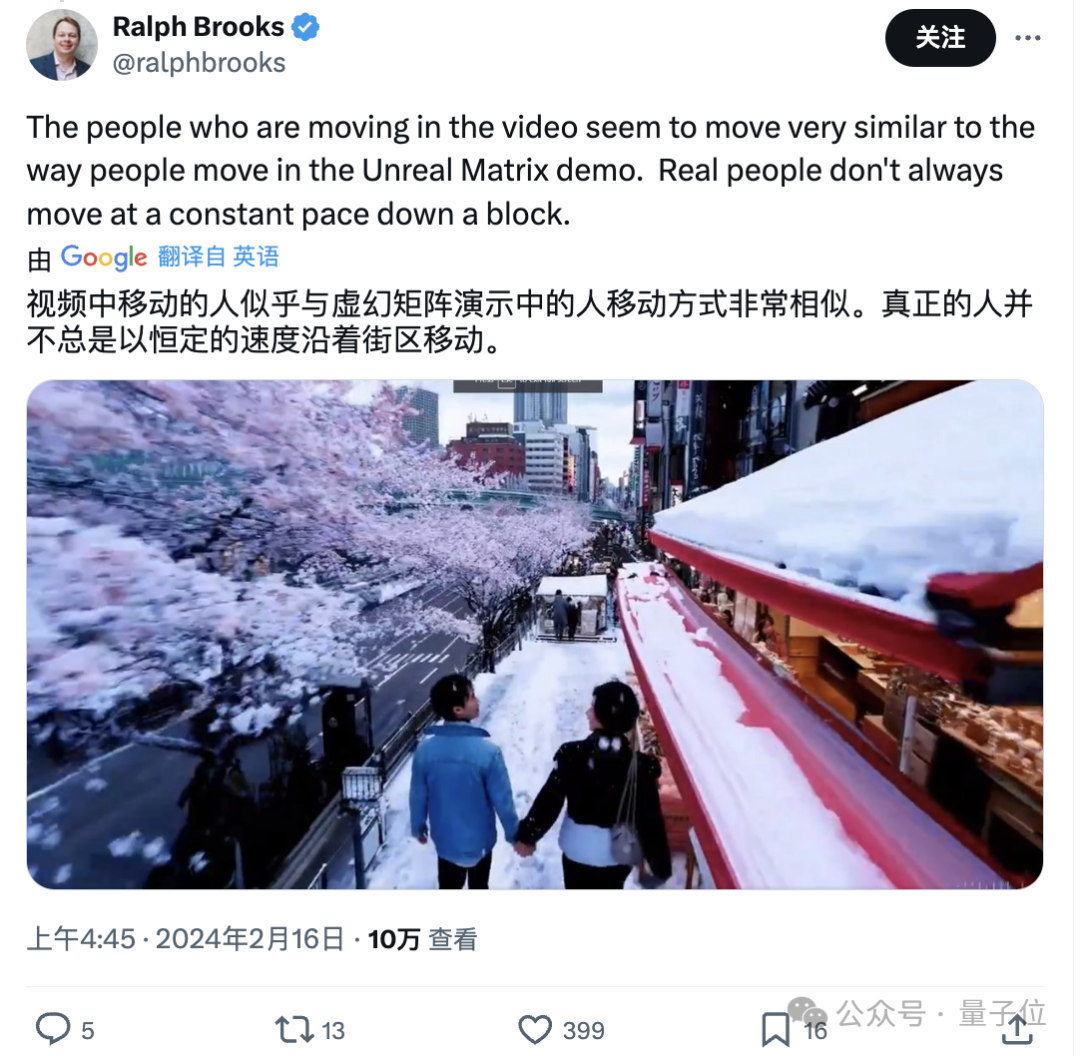
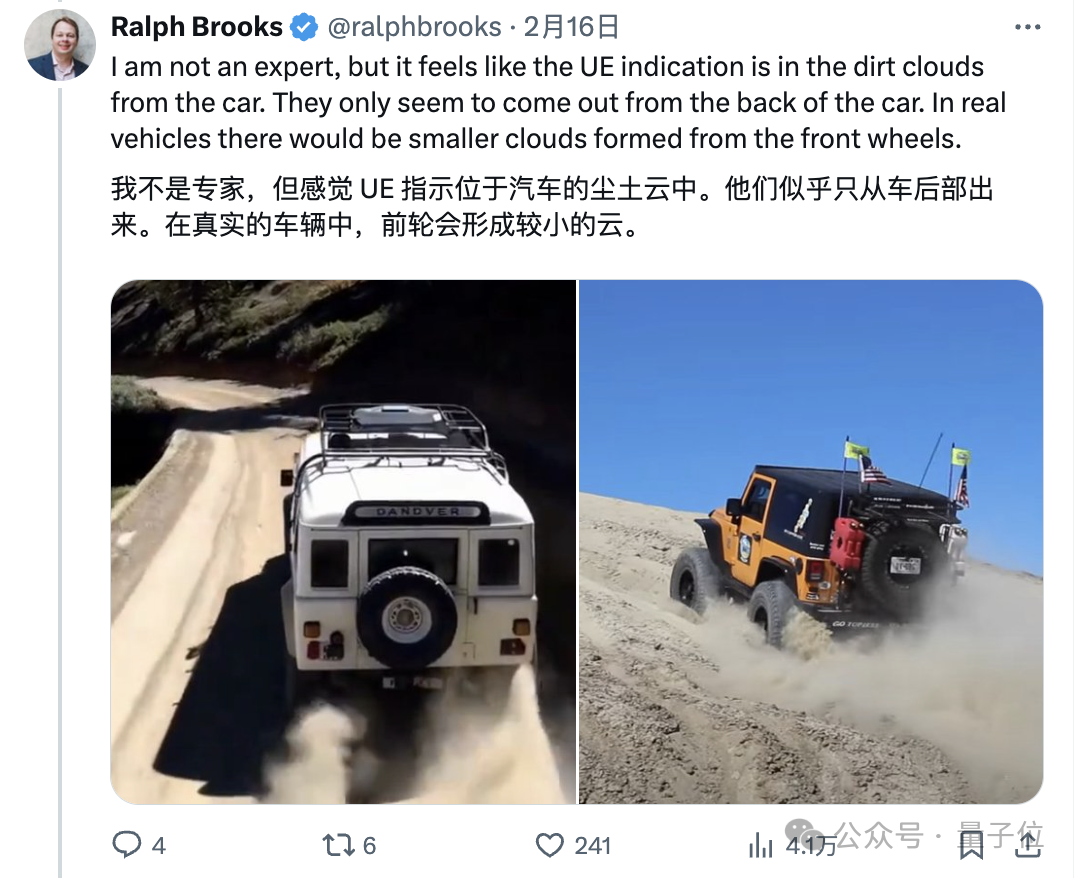
除此之外,还有胆大的网友甚至怀疑Sora用上了虚幻引擎5来创建部分训练数据。


如此种种,暂且不论。

随着最新一要约收购完成,OpenAI的估值正式达到800亿美元,仅次于字节跳动和SpaceX。
这笔交易由风投公司ThriveCapital牵头,外部投资者可以从一些员工手中购买股份,去年年初时OpenAI就完成过类似交易,使其当时的估值达到290亿美元。
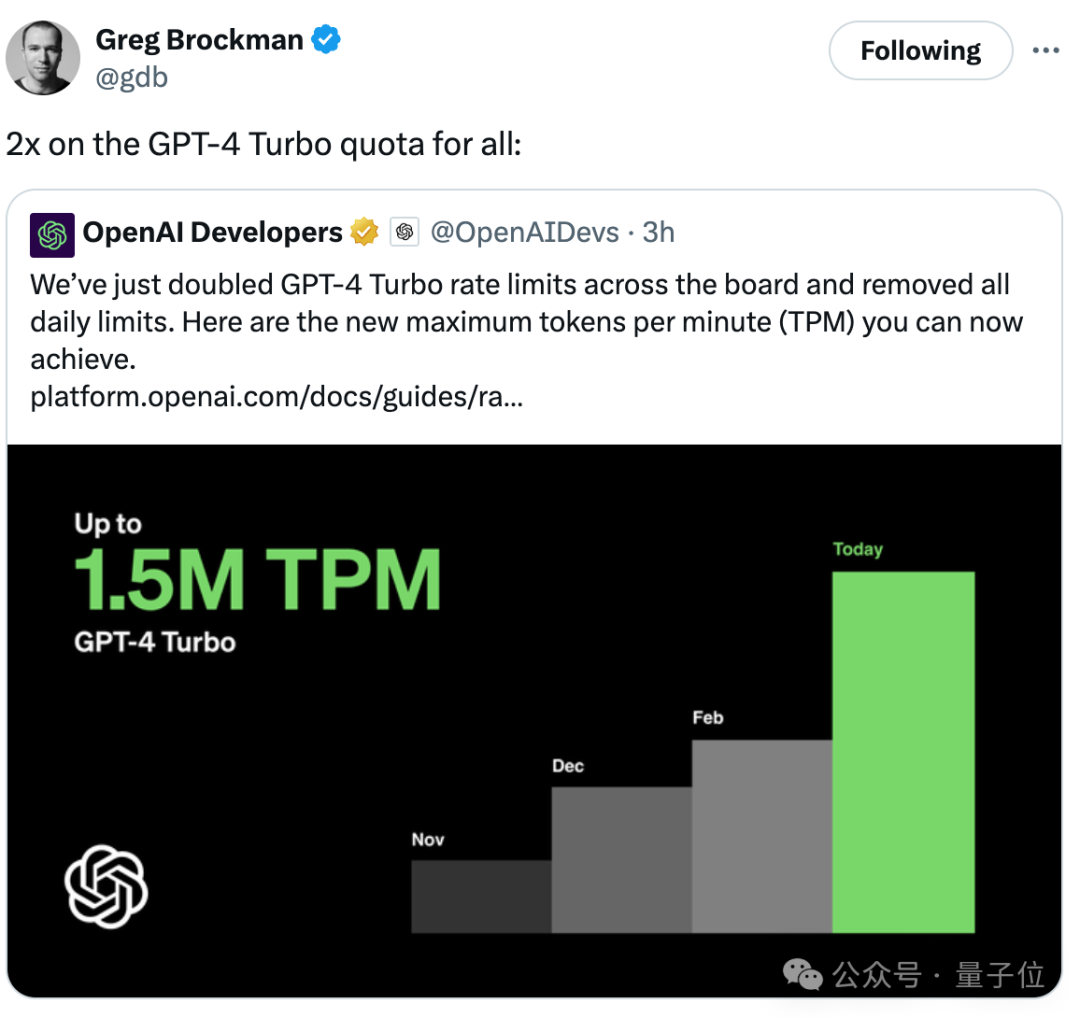
而在Sora发布后,GPT-4Turbo也大幅降低速率限制,提高TPM(每分钟最大token数量),较上一次实现2倍提升。
总裁Brockman还亲自带货宣传。
但与此同时,
OpenAI申请注册“GPT”商标失败了。
理由是“GPT”太通用。
OneMoreThing值得一提的是,有眼尖的网友发现,昨天StabilityAI也发布了。
但似乎在Sora发布不久后火速删博。
有人锐评,这不是翻版汪峰么?不应该删,应该返蹭个热度。
还有人感慨,Sora一来,立马就明白张楠为啥要聚焦剪映了。
以及卖课大军也闻风而动,把商机拿捏死死的(doge)。
参考链接:
[1]
[2]
[3]
[4]
[5]
—完—





